Python---微信公众号或网页自动导出
背景
从来没有这么粉过一位公众号作者,嗯。。。确切的说是女朋友那天和我说喜欢看一位公众号的作者,然后觉得微信的机制很不好,每次都要翻啊翻,想想有个办法能导出就好了。网上确实有人在做这件事,不过是收费的,具体是谁博主就不点名啦。额。。。我好想能做出来,话不多说,我先试为敬。
所以呢本文主要就是来说说,如何把自己喜欢的网页导出成为pdf,自己喜欢的公众号导出成pdf,让自己随时想看随时看,不受微信的约束,不受各个网站流量的约束。
展示效果
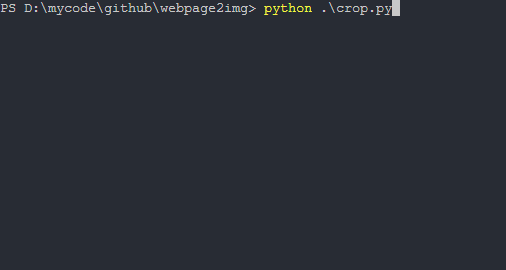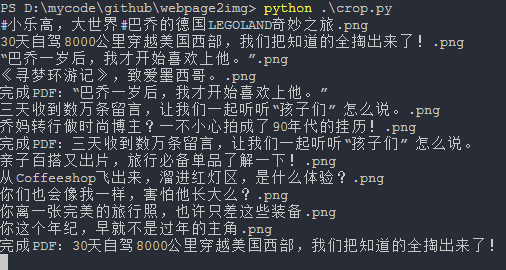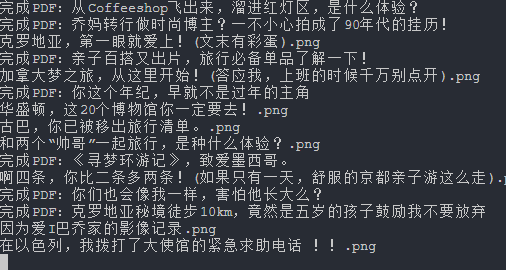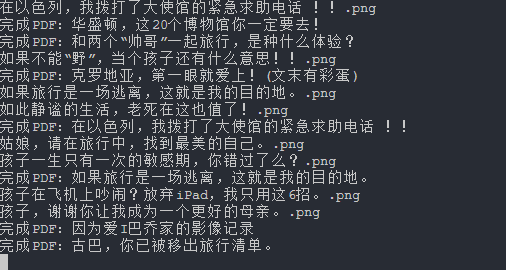
项目地址
思路
其实微信这个平台流量巨大,微信想怎么限制怎么限制,比如最近封杀抖音,还有和支付宝的战争。所以其实微信对于反爬,等一些功能做了比较好的限制。
正面突破也是可以,如何攻破微信的一项一项障碍,最终直接爬取。
本文的总体思路如下:
利用python webdriver库来动态的滚动网页,然后自动截图,保存。
然后利用截图进行裁切,计算页面大小,存为pdf
环境
- Python3
- webdriver(安装详见:官网地址)
- pillow图片加载库
pip install pillow
嗯。。。别的暂时还没想起来
关键代码截取
init_filelist()
#首先初始化webdirver
driver = webdriver.Chrome()
#设置输出路径
dir = './result'
for item in filelist:
try:
#获取图片路径,标题,以及输出路径
#自动滚动,并截图保存
pic_path,title = save_url(driver, item, dir)
#开始合并我们刚刚截的所有图
package_picture(pic_path, os.path.abspath(dir), title)
except Exception as e :
print(e)
save_url方法内部主要步骤如下
- 首先利用xpath找到微信公众号标题,“//div//h2[@class=‘rich_media_title’]”
- 然后将标题设置为文件名
- 再然后自动滚动屏幕
- 保存每一次滚动屏幕的图片
package_picture方法内部主要步骤如下
- 将刚刚保存的分散的图片打包成为整体
- 存入./result文件夹内
长图转为pdf
获取到长图了之后,那么接下来的工作就是转换为pdf了
执行以下命令
python crop.py
这个命令的目的是将刚刚我们的所有图片做成一个个单独的pdf,再次要感谢网友“TTyb”,
以下内容参考了他的博客
写在结尾
消失了几个月的博主,今天好像回来了,嗯。。。感慨颇多。
希望以后不止分享逆向的东西,把博主的所见所闻一起分享给大家。
好玩的有趣的,各种各样的。
是不是有的小伙伴是不是不愿意这样呢,还是没有呢。
看心情,看缘分啦。
佛系的博主
写完博客转眼已经第二天啦。
2018.7.17
关于我
个人网站:MartinHan的小站
知乎:MartinHan01